Experimentele de la Large Hadron Collider produc aproximativ un milion de gigaocteti de date în fiecare secundă. Chiar și după filtrare și compresie, datele acumulate în doar o oră sunt similare cu volumul de date colectat de Facebook într-un an întreg.
 Din fericire, fizicienii nu trebuie să proceseze și să analizeze aceste date singuri. Ei sunt ajutați de software de “Machine learning” care învață cum să facă analize complexe pe cont propriu.
Din fericire, fizicienii nu trebuie să proceseze și să analizeze aceste date singuri. Ei sunt ajutați de software de “Machine learning” care învață cum să facă analize complexe pe cont propriu.
“În comparație cu un algoritm obișnuit de calculator pe care-l proiectăm pentru o analiză specifică, algoritmii folosiți de noi trebuie proiectați pentru a ne da seama cum să facem diferite analize, salvând nenumărate ore de muncă”, spune fizicianul Alexander Radovic ce lucrează la experimentul NOvA.
Radovic împreună cu un grup de cercetători au descris aplicațiile actuale și perspectivele viitoare de învățare a mașinilor în fizica particulelor într-o lucrare publicată în revista Nature.
Căutarea în “Big Data”
Pentru a face față volumului de date uriaș produs în experimentele moderne, cum ar fi cele de la LHC, cercetătorii folosesc ceea ce se numesc “triggere” (declanșatoare) hardware și software, care decid în timp real ce date să păstreze pentru analiză și ce date să fie eliminate.
 La LHCb, un experiment care ar putea explica de ce există mai multă materie decât antimaterie în Univers, algoritmii iau cel puțin 70% din decizii, spune Mike Williams de la MIT. “Machine learning joacă un rol important în aproape toate aspectele legate de datele experimentului, de la triggere la analiza datelor rămase”, spune Williams.
La LHCb, un experiment care ar putea explica de ce există mai multă materie decât antimaterie în Univers, algoritmii iau cel puțin 70% din decizii, spune Mike Williams de la MIT. “Machine learning joacă un rol important în aproape toate aspectele legate de datele experimentului, de la triggere la analiza datelor rămase”, spune Williams.
Machine learning s-a dovedit a fi extrem de utilă în domeniul analizei. Detectorii giganți de la LHC, ATLAS și CMS, care au permis descoperirea bosonului Higgs, au fiecare zeci de milioane de elemente de detecție ale căror semnale trebuie să fie colectate și puse cap la cap.
“Aceste semnale alcătuiesc un spațiu complex de date”, spune Michael Kagan de la “US Department of Energy’s SLAC National Accelerator Laboratory”, care lucrează la ATLAS și este co-autor al lucrării mai sus menționate din revista Nature. “Trebuie să înțelegem relația dintre semnale pentru a veni cu concluzii – de exemplu, dacă o anumită urmă detectată a fost produsă de un electron, un foton sau altceva.”
Și NOvA, beneficiază de avantajul folosirii inteligenței artificiale și a machine learning-ului. Fermilab – ce gestionează experimentele NOvA – studiază modul în care neutrinii se schimbă dintr-un tip într-altul în timp ce călătoresc prin Pământ. Aceste oscilații neutrinice ar putea să dezvăluie existența unui nou tip de neutrino pe care unele teorii o prezic a fi o particulă a materiei întunecate. Detectoarele NOvA urmăresc particulele încărcate atunci când neutrinii au lovit materialul detectorului, iar algoritmii de machine learning le-au identificat.
Large Hadron Collider
LHC este cel mai mare accelerator de particule din lume și cel care atinge cele mai mari energii. Colierul se află într-un tunel circular, cu o circumferința de 27 km, aflat la o adâncime intre 50-175 m sub pământ.
 Tunelul este compus din două țevi inelare adiacente separate care se intersectează în patru puncte, fiecare țeavă conținând o conductă de protoni. Aceștia se deplasează în tunel în direcții opuse. Aproximativ 1232 dipoli magnetici păstrează fluxurile pe calea lor circulară și 392 cuadripoli magnetici sunt utilizați pentru a păstra fluxurile focalizate. În total sunt instalați peste 1600 magneți supraconductori, majoritatea cântărind peste 27 tone.
Tunelul este compus din două țevi inelare adiacente separate care se intersectează în patru puncte, fiecare țeavă conținând o conductă de protoni. Aceștia se deplasează în tunel în direcții opuse. Aproximativ 1232 dipoli magnetici păstrează fluxurile pe calea lor circulară și 392 cuadripoli magnetici sunt utilizați pentru a păstra fluxurile focalizate. În total sunt instalați peste 1600 magneți supraconductori, majoritatea cântărind peste 27 tone.
O dată sau de două ori pe zi, în timp ce protonii sunt accelerați de la 450 GeV pana la cel mult 7 TeV, câmpurile magnetice ale dipolilor electromagnetici supraconductori sunt mărite de la 0,54 la 8,3 tesla. Protonii pot ajunge fiecare pana la o energie de 7 TeV, energia totală de coliziune ajungând astfel pana la 14 TeV. La acest nivel de energie, protonii se deplasează cu viteze de 99,999999% din viteza luminii. Durează mai putin de 90 μs ca un proton sa efectueze o tura în inelului principal – viteza sa unghiulara putând ajunge la 11.000 revoluții pe secunda.
Programul de la LHC se bazează mai ales pe coliziuni proton-proton. Totuși sunt incluse în program și perioade de rulare mai scurte, de regula o luna pe an, cu coliziuni de ioni grei. Deși și ionii mai ușori sunt luați în considerare, scopul principal al acestor perioade de rulare îl reprezintă ionii de plumb. Scopul programului cu ioni grei este observarea unei stări a materiei numită plasma quark-gluon, care caracteriza etapa inițială a existenței Universului, imediat după Big Bang.
Un boson Higgs este produs o dată la câteva miliarde de ciocniri proton-proton. Pentru a permite eșantioanelor de date sa fie înregistrate într-un interval de timp rezonabil, LHC ciocnește aproape 1 miliard de protoni pe secundă.
 Aceste coliziuni pot produce sute de particule și studierea dezintegrării lor necesită detectori puternici dotați cu diverse matrici de senzori. Detectorii ATLAS și CMS conțin fiecare aproximativ 100 de milioane de elemente de detecție.
Aceste coliziuni pot produce sute de particule și studierea dezintegrării lor necesită detectori puternici dotați cu diverse matrici de senzori. Detectorii ATLAS și CMS conțin fiecare aproximativ 100 de milioane de elemente de detecție.
Studiul cuarcurilor prezintă un interes deosebit pentru LHC deoarece aceste particule sunt produse frecvent prin dezintegrarea bosonului Higgs. Un cuarc radiază o parte substanțială a energiei sale sub forma unui flux de particule colimate, precum un jet, înainte să întâlnească un anticuarc sau un alt cuarc. Radiația este emisa pe o distanta aproximativ de dimensiunea unui proton, făcând acest lucru imposibil de observat în mod direct și „trăiește” doar o picosecundă înainte sa se dezintegreze din nou. Așadar, pentru a identifica jeturile care provin de la cuarcuri, este necesar sa se poată stabili dacă particulele au fost produse direct în coliziunea proton-proton.
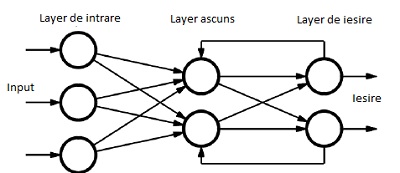 Recurrent Neural Networks
Recurrent Neural Networks
Recurrent Neural Networks (RNN) s-au dovedit a fi eficiente în procesarea secvențelor mari de date. RNN este folosit și de Google în serviciul lor de traduceri. Folosirea RNN pentru clasificarea jeturilor necesită ca particulele să fie ordonate pentru a forma o secvență. Un set de caracteristici pentru fiecare particulă este oferit RNN-ului, ce este antrenat pentru a face diferența între jetul lăsat de cuarcul de tip farmec și alte jeturi. Folosirea RNN-ului în cadrul experimentului ATLAS a redus mult rata de interpretare greșită.
Antrenare și validare
Rețelele neurale folosite în fizica particulelor sunt de obicei instruite prin învățarea supravegheata și se antrenează folosind date de test ce conțin proprietățile particulelor și alte informații necesare. Exista întotdeauna posibilitatea ca anumite caracteristici introduse în date sa nu fie modelate corect și să poată duce la detectări false.
De la „Machine learning” la „Deep learning”
Cele mai noi metode de “Machine Learning”, adesea numite “Deep Learning”, promit să ducă fizica particulelor la un nou nivel. Deep learning se referă în general la utilizarea rețelelor neuronale: algoritmi de calcul cu o arhitectura inspirată din rețeaua densă de neuroni din creierul uman.
Aceste rețele neuronale învață pe cont propriu cum sa realizeze anumite sarcini de analiza în timpul perioadei de antrenare în care sunt prezentate date de test, cum ar fi simulările, și li se spune cât de bine s-au descurcat.
“Până de curând, succesul rețelelor neuronale a fost limitat, deoarece antrenarea acestora era foarte greoaie și necesită multe resurse”, spune co-autorul lucrării Kazuhiro Terao, cercetător SLAC. “Aceste dificultăți ne-au limitat la doar câteva straturi de neuroni (layere). Datorită îmbunatățirii algoritmilor dar și a hardware-ului, acum putem să construim și să instruim rețele mai capabile formate din sute sau mii de straturi de neuroni”.
Multe dintre progresele înregistrate în domeniul Machine Learning-ului sunt determinate de aplicațiile comerciale ale giganților de software și de explozia de date generată de oameni în ultimele doua decenii. “NOvA, de exemplu, utilizează o rețea neuronala inspirată de arhitectura GoogleNet”, spune Radovic. “A îmbunătățit experimentul în moduri care altfel ar fi putut fi obținute doar prin colectarea a 30% mai multe date”.
Un teren fertil pentru inovație
Algoritmii de Machine learning devin din ce în ce mai sofisticați deschizând oportunități fără precedent pentru a rezolva probleme în fizica particulelor.
Multe dintre problemele noi unde ar putea fi folosite sunt legate de “computer vision”, spune Kagan. “Este similar cu recunoașterea facială, cu excepția faptului ca în fizica particulelor, trăsăturile imaginii sunt mai abstracte și mai complexe decât urechile și nasul”.
Unele experimente precum NOvA și MicroBooNE produc date care pot fi ușor transformate în imagini reale, iar algoritmii pot identifica caracteristicile din aceste imagini. În experimentele de la LHC, pe de altă parte, imaginile trebuie mai întâi reconstruite din foarte multe date generate de milioane de senzori.
“Chiar dacă datele nu arată ca imagini, putem folosi în continuare metode de vizionare a datelor dacă le putem procesa în mod corect”, spune Radovic.
Un domeniu în care această abordare ar putea fi utilă este analiza jeturilor de particule produse în număr mare la LHC.
Scepticismul asupra Machine learning-ului
În ciuda tuturor progreselor evidente, pasionații de Machine Learning se confruntă frecvent cu scepticismul partenerilor lor de colaborare deoarece algoritmii de învățare sunt precum o cutie neagră care oferă foarte puține informații despre cum au ajuns la o anumită concluzie.
“Scepticismul este foarte sănătos”, spune Williams. “Dacă folosiți Machine learning pentru triggere care elimina datele, așa cum facem în LHCb, atunci doriți să fiți extrem de precaut.”
Prin urmare, antrenarea rețelelor necesită eforturi constante pentru a înțelege mai bine funcționarea algoritmilor și pentru a face verificări încrucișate cu date reale ori de câte ori este posibil.
“Ar trebui să încercam mereu să înțelegem ce face un algoritm și să evaluăm întotdeauna rezultatul său”, spune Terao. “Acest lucru este valabil pentru fiecare algoritm, nu numai pentru machine learning. Deci, a fii sceptic nu ar trebui să oprească progresul.”
Progresele rapide au făcut pe unii cercetători să viseze la ceea ce ar putea deveni posibil în viitorul apropiat. “Astăzi folosim machine learning pentru a găsi caracteristici în datele noastre care ne pot ajuta să răspundem la unele dintre întrebările noastre”, spune Terao. “Zece ani de acum, algoritmii de învățare ar putea sa-și pună propriile întrebări în mod independent și sa recunoască atunci când descoperă ceva”.
Bibliografie:
https://www.symmetrymagazine.org
https://www.nature.com/articles/s41586-018-0361-2









{kind=link}